
(SEO实战密码 电子工业出版社 2011年1月出版)
作者信息:
昝辉,网名Zac,1992年毕业于北京航空航天大学电子工程系,1995年北京电影学院硕士研究生毕业。1997来到新加坡在后期制作公司担任编辑和项目经理等职务。Zac于2006年开始写中文博客《SEO每天一贴》。几个月内《SEO每天一贴》成为中国SEO领域被引用最多,最受欢迎的行业博客之一,很多文章在网上广为流传。
注明:本文由电子工业出版社授权站长之家连载,未经授权请勿转载。文章内容节选自《SEO实战密码》第二章节。
搜索引擎工作过程非常复杂,接下来的几节我们简单介绍搜索引擎是怎样实现网页排名的。这里介绍的内容相对于真正的搜索引擎技术来说只是皮毛,不过对SEO人员已经足够用了。
搜索引擎的工作过程大体上可以分成三个阶段。
(1)爬行和抓取:搜索引擎蜘蛛通过跟踪链接访问网页,获得页面HTML代码存入数据库。
(2)预处理:索引程序对抓取来的页面数据进行文字提取、中文分词、索引等处理,以备排名程序调用。
(3)排名:用户输入关键词后,排名程序调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取
爬行和抓取是搜索引擎工作的第一步,完成数据收集的任务。
1.蜘蛛
搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。
搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序把收到的代码存入原始页面数据库。搜索引擎为了提高爬行和抓取速度,都使用多个蜘蛛并发分布爬行。
蜘蛛访问任何一个网站时,都会先访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些文件或目录,蜘蛛将遵守协议,不抓取被禁止的网址。
和浏览器一样,搜索引擎蜘蛛也有标明自己身份的代理名称,站长可以在日志文件中看到搜索引擎的特定代理名称,从而辨识搜索引擎蜘蛛。下面列出常见的搜索引擎蜘蛛名称:
· Baiduspider+(+http://www.baidu.com/search/spider.htm) 百度蜘蛛
· Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html) 雅虎中国蜘蛛
· Mozilla/5.0 (compatible; Yahoo! Slurp/3.0; http://help.yahoo.com/help/us/ysearch/slurp) 英文雅虎蜘蛛
· Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) Google蜘蛛
· msnbot/1.1 (+http://search.msn.com/msnbot.htm) 微软 Bing蜘蛛
· Sogou+web+robot+(+http://www.sogou.com/docs/help/webmasters.htm#07)搜狗蜘蛛
· Sosospider+(+http://help.soso.com/webspider.htm) 搜搜蜘蛛
· Mozilla/5.0 (compatible; YodaoBot/1.0; http://www.yodao.com/help/webmaster/spider/; ) 有道蜘蛛
2.跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。
整个互联网是由相互链接的网站及页面组成的。从理论上说,蜘蛛从任何一个页面出发,顺着链接都可以爬行到网上的所有页面。当然,由于网站及页面链接结构异常复杂,蜘蛛需要采取一定的爬行策略才能遍历网上所有页面。
最简单的爬行遍历策略分为两种,一种是深度优先,另一种是广度优先。
所谓深度优先,指的是蜘蛛沿着发现的链接一直向前爬行,直到前面再也没有其他链接,然后返回到第一个页面,沿着另一个链接再一直往前爬行。
如图2-20所示,蜘蛛跟踪链接,从A页面爬行到A1,A2,A3,A4,到A4页面后,已经没有其他链接可以跟踪就返回A页面,顺着页面上的另一个链接,爬行到B1,B2,B3,B4。在深度优先策略中,蜘蛛一直爬到无法再向前,才返回爬另一条线。
广度优先是指蜘蛛在一个页面上发现多个链接时,不是顺着一个链接一直向前,而是把页面上所有第一层链接都爬一遍,然后再沿着第二层页面上发现的链接爬向第三层页面。
如图2-21所示,蜘蛛从A页面顺着链接爬行到A1,B1,C1页面,直到A页面上的所有链接都爬行完,然后再从A1页面发现的下一层链接,爬行到A2,A3,A4,……页面。
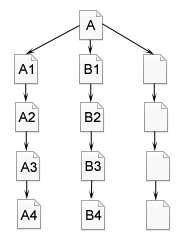
图2-20 深度优先遍历策略
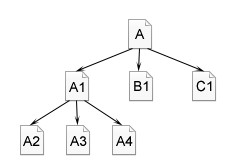
图2-21 广度优先遍历策略
从理论上说,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,都能爬完整个互联网。在实际工作中,蜘蛛的带宽资源、时间都不是无限的,也不可能爬完所有页面。实际上最大的搜索引擎也只是爬行和收录了互联网的一小部分。
深度优先和广度优先通常是混合使用的,这样既可以照顾到尽量多的网站(广度优先),也能照顾到一部分网站的内页(深度优先)。
3.吸引蜘蛛
由此可见,虽然理论上蜘蛛能爬行和抓取所有页面,但实际上不能、也不会这么做。SEO人员要想让自己的更多页面被收录,就要想方设法吸引蜘蛛来抓取。既然不能抓取所有页面,蜘蛛所要做的就是尽量抓取重要页面。哪些页面被认为比较重要呢?有几方面影响因素。
1、网站和页面权重。质量高、资格老的网站被认为权重比较高,这种网站上的页面被爬行的深度也会比较高,所以会有更多内页被收录。
2、页面更新度。蜘蛛每次爬行都会把页面数据存储起来。如果第二次爬行发现页面与第一次收录的完全一样,说明页面没有更新,蜘蛛也就没有必要经常抓取。如果页面内容经常更新,蜘蛛就会更加频繁地访问这种页面,页面上出现的新链接,也自然会被蜘蛛更快地跟踪,抓取新页面。
3、导入链接。无论是外部链接还是同一个网站的内部链接,要被蜘蛛抓取,就必须有导入链接进入页面,否则蜘蛛根本没有机会知道页面的存在。高质量的导入链接也经常使页面上的导出链接被爬行深度增加。
4、与首页点击距离。一般来说网站上权重最高的是首页,大部分外部链接是指向首页的,蜘蛛访问最频繁的也是首页。离首页点击距离越近,页面权重越高,被蜘蛛爬行的机会也越大。
4.地址库
为了避免重复爬行和抓取网址,搜索引擎会建立一个地址库,记录已经被发现还没有抓取的页面,以及已经被抓取的页面。
地址库中的URL有几个来源:
(1)人工录入的种子网站。
(2)蜘蛛抓取页面后,从HTML中解析出新的链接URL,与地址库中的数据进行对比,如果是地址库中没有的网址,就存入待访问地址库。
(3)站长通过搜索引擎网页提交表格提交进来的网址。
蜘蛛按重要性从待访问地址库中提取URL,访问并抓取页面,然后把这个URL从待访问地址库中删除,放进已访问地址库中。
大部分主流搜索引擎都提供一个表格,让站长提交网址。不过这些提交来的网址都只是存入地址库而已,是否收录还要看页面重要性如何。搜索引擎所收录的绝大部分页面是蜘蛛自己跟踪链接得到的。可以说提交页面基本上是毫无用处的,搜索引擎更喜欢自己沿着链接发现新页面。
5.文件存储
搜索引擎蜘蛛抓取的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。每个URL都有一个独特的文件编号。
6.爬行时的复制内容检测
检测并删除复制内容通常是在下面介绍的预处理过程中进行的,但现在的蜘蛛在爬行和抓取文件时也会进行一定程度的复制内容检测。遇到权重很低的网站上大量转载或抄袭内容时,很可能不再继续爬行。这也就是有的站长在日志文件中发现了蜘蛛,但页面从来没有被真正收录过的原因。

