测试观察对象主要为百度和Google,测试页面也将永久保留,方便以后观察。 先来回顾一下这三组测试,第三组是4月10日才加上去的。
第一组:分为页面 1 和 2 ,测试搜索引擎是如何对待和识别普通html页面的跳转。方法就是在页面 1 加上下面这段meta标签代码,跳转到页面 2 :
| <meta http-equiv="refresh" content="10;URL=跳转结果页面地址"> |
第二组:分为页面 3 和 4 ,测试搜索引擎是如何对待和识别Javascript的跳转。方法就是在页面 3 加上下面这段JS跳转代码,跳转到页面 4 :
| <script language="javascript"> var the_timeout = setTimeout("location='跳转结果页面地址'",10000); </script> |
第三组:分为页面 5 和 6 ,测试搜索引擎是如何对待和识别外调JS的跳转。方法是在页面 5 加上下面这段外调JS代码(外调的JS包含跳转代码),跳转到页面 6 :
|
<script src=http://www.chinaz.com/Webbiz/Exp/"http://***.com/qita/ceshi/tiao/5-2.htm"></script> |
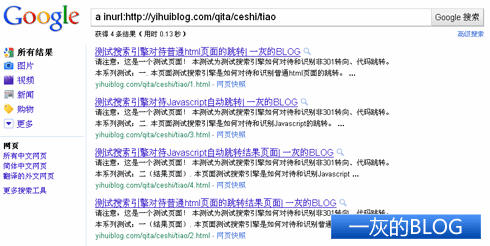
再来看看这三组页面之前的收录。 Google方面,刚开始是 1 、2 、3 、4 四个页面都收录了,再后来是删掉了 1 和 3 两个页面。后来再到第三组的时候,直到现在都只是收录了 5 这个页面,虽然Google蜘蛛已经爬过了 5-2 这个外调的JS。

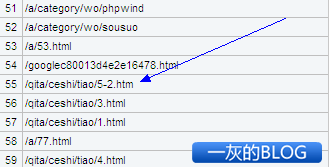
5-2 页面捉取的日志代码如下:
| 66.249.68.198 - - 19/Apr/2011:07:01:44 -0700 "GET /qita/ceshi/tiao/5-2.htm HTTP/1.1" 200 153 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" |
目前那三组测试页面,Google方面收录了2 、4 、5 三个页面。
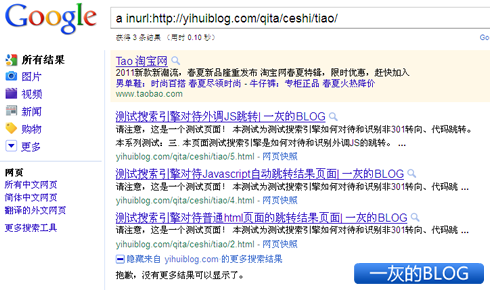
百度方面,主机日志显示百度蜘蛛爬过 1 、2 、3 、5 这四个页面,但目前从site的结果来看,只收录了2、3、5三个页面。
好了,终于写到这个系列测试的总结部分,估计那么长大家看得头晕晕了。
本测试已经尽量避免搜索引擎从其他地方获取跳转结果页面。退一万步来说,被搜索引擎从其他地方获取了跳转结果页面导致捉取索引,就算“识别”测试部分失败也剩下“对待”测试部分。
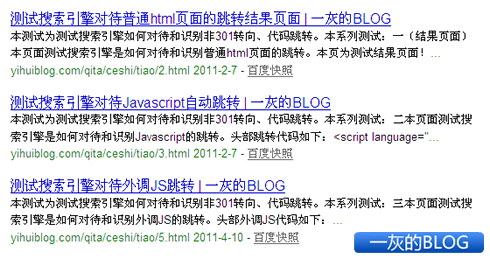
第一组测试结果:百度和Google都可以很好地识别普通html页面的跳转,也将之视为 301 重定向效果,不收录页面 1 。
第二组测试结果:百度方面方面,就算页面内部的JS代码,也不会去分析和对其中的链接进行(页面 4 )捉取。Google方面则不同,完全识别到这段网页里面的JS跳转代码,也将之视为 301 重定向效果,不收录页面 3 。
第三组测试结果:百度和Google都没有分析出页面 6 进行捉取和索引。唯一不同的是Google会捉取外调的JS页面 5-2 。
相信这个系列的测试对很多人都有启发。当然没有东西是十全十美的,这个系列的测试也不例外。欢迎探讨交流,分享这个系列测试的经验心得。
原文地址:http://yihuiblog.com/a/78.html ,请尊重版权。
感谢 yihuiblog 的投稿

