在讲淘宝文件系统TFS之前,先回顾一下上面几个版本。1.0版的PHP系统运行了将近一年的时间(2003.05-2004.01);后来数据库变成Oracle之后(2004.01-2004.05,叫1.1版本吧),不到半年就把开发语言转换为Java系统了(2004.02-2005.03,叫2.0版本);进行分库、加入缓存、CDN之后我们叫它2.1版本(2004.10-2007.01)。这中间有些时间的重合,因为很多架构的演化并没有明显的时间点,它是逐步进化而来的。
在描述2.1版本的时候我写的副标题是“坚若磐石”,这个“坚若磐石”是因为这个版本终于稳定下来了,在这个版本的系统上,淘宝网运行了两年多的时间。这期间有很多优秀的人才加入,也开发了很多优秀的产品,例如支付宝认证系统、招财进宝项目、淘宝旅行、淘宝彩票、淘宝论坛等等。甚至在团购网站风起云涌之前,淘宝网在2006年就推出了团购的功能,只是淘宝网最初的团购功能是买家发起的,达到卖家指定的数量之后,享受比一口价更低的价格,这个功能看起来是结合了淘宝一口价和荷兰拍的另一种交易模式,但不幸没有支撑下去。
在这些产品和功能的最底层,其实还是商品的管理和交易的管理这两大功能。这两大功能在2.1版本里面都有很大的变化。商品的管理起初是要求卖家选择7天到期还是14天到期,到期之后就要下架,必须重新发布才能上架,上架之后就变成了新的商品信息(ID变过了)。另外如果这个期间内成交了,之后再有新货,必须发布一个新的商品信息。这么做有几个原因,一是参照拍卖商品的时间设置,要在某日期前结束挂牌;二是搜索引擎不知道同样的商品哪个排前面,那就把挂牌时间长的排前面,这样就必须在某个时间把老的商品下架掉,不然它老排在前面;第三是成交信息和商品ID关联,这个商品如果多次编辑还是同一个ID的话,成交记录里面的商品信息会变来变去;还有一个不为人知的原因,我们的存储有限,不能让所有的商品老存放在主库里面。这种处理方式简单粗暴,但还算是公平。不过这样很多需求都无法满足,例如同样的商品,我上一次销售的时候很多好评都没法在下一个商品上体现出来;再例如我买过的商品结束后只看到交易的信息,不知道卖家还有没有再卖了。后来基于这些需求,我们在2006年下半年把商品和交易拆开。一个商家的一种商品有个唯一的ID,上下架都是同一个商品。那么如果卖家改价格、库存什么的话,已成交的信息怎么处理?那就在买家每交易一次的时候,都记录下商品的快照信息,有多少次交易就有多少个快照。这样买卖双方比较爽了,给系统带来了什么?存储的成本大幅度上升了!
存储的成本高到什么程度呢?数据库方面提到过用了IOE,一套下来就是千万级别的,那几套下来就是⋯⋯。另外淘宝网还有很多文件需要存储,我们有哪些文件呢?最主要的就是图片、商品描述、交易快照,一个商品要包含几张图片和一长串的描述信息,而每一张图片都要生成几张规格不同的缩略图。在2010年,淘宝网的后端系统上保存着286亿个图片文件。图片在交易系统中非常重要,俗话说“一张好图胜千言”、“无图无真相”,淘宝网的商品照片,尤其是热门商品,图片的访问流量是非常大的。淘宝网整体流量中,图片的访问流量要占到90%以上。且这些图片平均大小为17.45KB,小于8K的图片占整体图片数量61%,占整体系统容量的11%。这么多的图片数据、这么大的访问流量,给淘宝网的系统带来了巨大的挑战。众所周知,对于大多数系统来说,最头疼的就是大规模的小文件存储与读取,因为磁头需要频繁的寻道和换道,因此在读取上容易带来较长的延时。在大量高并发访问量的情况下,简直就是系统的噩梦。我们该怎么办?
同样的套路,在某个规模以下,采用现有的商业解决方案,达到某种规模之后,商业的解决方案无法满足,只有自己创造解决方案了。对于淘宝的图片存储来说,转折点在2007年。这之前,一直采用的商用存储系统,应用NetApp公司的文件存储系统。随着淘宝网的图片文件数量以每年2倍(即原来3倍)的速度增长,淘宝网后端NetApp公司的存储系统也从低端到高端不断迁移,直至2006年,即使是NetApp公司最高端的产品也不能满足淘宝网存储的要求。从2006年开始,淘宝网决定自己开发一套针对海量小文件存储的文件系统,用于解决自身图片存储的难题。这标志着淘宝网从使用技术到了创造技术的阶段。
2007年之前的图片存储架构如下图:
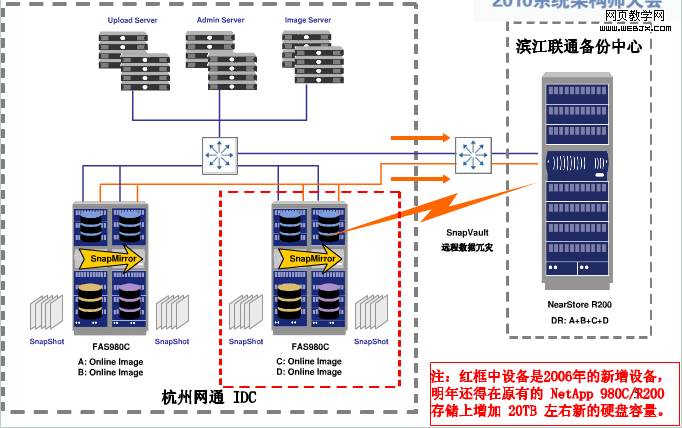
章文嵩博士总结了几点商用存储系统的局限和不足:
首先是商用的存储系统没有对小文件存储和读取的环境进行有针对性的优化;其次,文件数量大,网络存储设备无法支撑;另外,整个系统所连接的服务器也越来越多,网络连接数已经到达了网络存储设备的极限。此外,商用存储系统扩容成本高,10T的存储容量需要几百万,而且存在单点故障,容灾和安全性无法得到很好的保证。
谈到在商用系统和自主研发之间的经济效益对比,章文嵩博士列举了以下几点经验:
1.商用软件很难满足大规模系统的应用需求,无论存储还是CDN还是负载均衡,因为在厂商实验室端,很难实现如此大的数据规模测试。
2.研发过程中,将开源和自主开发相结合,会有更好的可控性,系统出问题了,完全可以从底层解决问题,系统扩展性也更高。
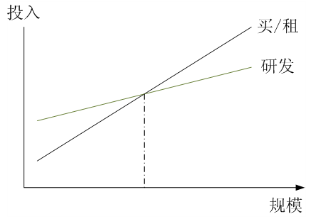
3.在一定规模效应基础上,研发的投入都是值得的。上图是一个自主研发和购买商用系统的投入产出比对比,实际上,在上图的交叉点左边,购买商用系统都是更加实际和经济性更好的选择,只有在规模超过交叉点的情况下,自主研发才能收到较好的经济效果。实际上,规模化达到如此程度的公司其实并不多,不过淘宝网已经远远超过了交叉点。
4.自主研发的系统可在软件和硬件多个层次不断的优化。
历史总是惊人的巧合,在我们准备研发文件存储系统的时候,google走在了前面,2007年他们公布了GFS( google file system )的设计论文,这给我们带来了很多借鉴的思路。随后我们开发出了适合淘宝使用的图片存储系统TFS( taobao file system )。3年之后,我们发现历史的巧合比我们想象中还要神奇,几乎跟我们同时,中国的另外一家互联网公司也开发了他们的文件存储系统,甚至取的名字都一样——TFS,太神奇了!(猜猜是哪家?)
2007年6月,TFS正式上线运营。在生产环境中应用的集群规模达到了200台PC Server(146G*6 SAS 15K Raid5),文件数量达到上亿级别;系统部署存储容量:140TB;实际使用存储容量: 50TB;单台支持随机IOPS 200+,流量3MBps。
要讲TFS的系统架构,首先要描述清楚业务需求,淘宝对图片存储的需求大概可以描述如下:
文件比较小;并发量高;读操作远大于写操作;访问随机;没有文件修改的操作;要求存储成本低;能容灾能备份。应对这种需求,显然要用分布式存储系统;由于文件大小比较统一,可以采用专有文件系统;并发量高,读写随机性强,需要更少的IO操作;考虑到成本和备份,需要用廉价的存储设备;考虑到容灾,需要能平滑扩容。
参照GFS并做了适度的优化之后,TFS1.0版的架构图如下:
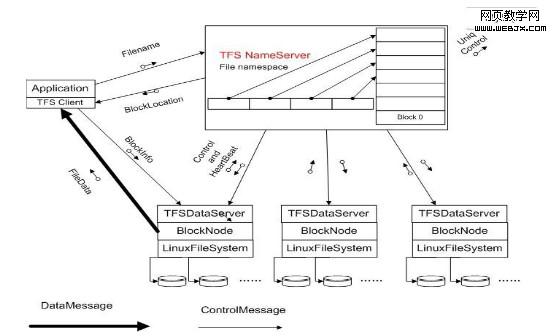
从上面架构图上看:集群由一对Name Server和多台Data Server构成,Name Server 的两台服务器互为双机,就是集群文件系统中管理节点的概念。
在这个架构中:
• 每个Data Server运行在一台普通的Linux主机上
• 以block文件的形式存放数据文件(一般64M一个block)
• block存多份保证数据安全
• 利用ext3文件系统存放数据文件
• 磁盘raid5做数据冗余
• 文件名内置元数据信息,用户自己保存TFS文件名与实际文件的对照关系–使得元数据量特别小。
淘宝TFS文件系统在核心设计上最大的取巧的地方就在,传统的集群系统里面元数据只有1份,通常由管理节点来管理,因而很容易成为瓶颈。而对于淘宝网的用户来说,图片文件究竟用什么名字来保存实际上用户并不关心,因此TFS在设计规划上考虑在图片的保存文件名上暗藏了一些元数据信息,例如图片的大小、时间、访问频次等等信息,包括所在的逻辑块号。而在元数据上,实际上保存的信息很少,因此元数据结构非常简单。仅仅只需要一个fileID,能够准确定位文件在什么地方。
由于大量的文件信息都隐藏在文件名中,整个系统完全抛弃了传统的目录树结构,因为目录树开销最大。拿掉后,整个集群的高可扩展性极大提高。实际上,这一设计理念和目前业界的“对象存储”较为类似,淘宝网TFS文件系统已经更新到1.3版本,在生产系统的性能已经得到验证,且不断得到了完善和优化,淘宝网目前在对象存储领域的研究已经走在前列。
1.3版本的架构见阿里味⋯⋯(编辑注:阿里味,淘宝内网 aliway.com)
作者:赵超

