大家都知道大概是“百度有啊”上线之前,淘宝网为了避免百度恶意抓取,直接屏蔽了百度蜘蛛,也就是当时闹得沸沸扬扬的robots.txt协议 。

就算是现在打开淘宝的robots.txt协议,依然可以看到淘宝还在屏蔽百度的蜘蛛。
可是事实上真的如此么
看下图

事实证明淘宝的robots.txt文件根本对百度蜘蛛起不到任何作用。
小弟推测百度之所以这么做是因为百度考虑到战略方向的问题,因为查询了一下发现一些知名店铺在百度的排名都很不错。足以证明百度对淘宝这种店铺的重要性。更加戏曲化的是天猫网(淘宝商城)也是使用robots.txt协议的。同样屏蔽了百度蜘蛛。

同样百度采取的态度是疯狂抓取 如图
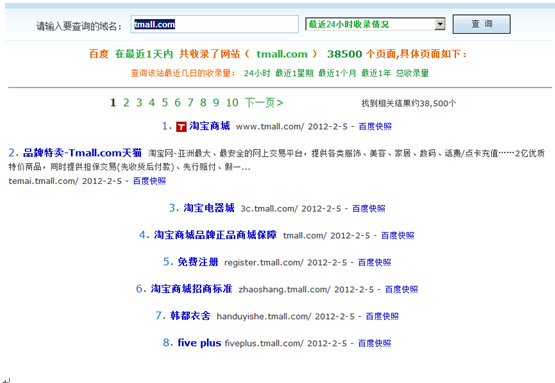
还有一种可能就是淘宝网以及天猫网的权重太高了,导致了百度蜘蛛不遵循搜索引擎协议而进行的抓取。不过对于这种事情可以联想到前些日子,一淘网恶意抓取京东商城以及新蛋网等的商品数据,也是不遵循搜索引擎规则的。
直到现在京东商城等也在屏蔽一淘网的蜘蛛,
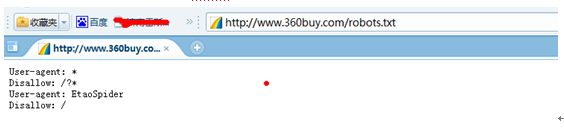
小编想说的是现在的搜索引擎为了自身利益而不遵循互联网协议的规则,是值得反思的,呼吁这种互联网大公司能在整个IT行业树立标榜。不要为了一己之私而不遵循游戏规则。本文由(www.591jiafa.com)供稿。

