很久没写什么东西了,简单写下,
1 百度收录的site查询是估值,灰常的估
2 最佳查询方式是进行定期抽查
3 去年年中时让邱森写了个简单的爬虫程序,用来抓取url+查询收录自动化实现,简单说下设计需求
a 指定一个url,作为开始抓取的起始点
b 指定一个必填字符串,一个选填字符串,在抓取过程中遇到url中包含上述两个字符串的,则进行记录,生成一个txt或csv文档,储存在指定位置
c 指定一个抓取和抽查的url条数,比如1000条
d 自定义百度的搜索结果页面采集规则
e 针对于抓取到的指定的url,采集百度搜索这些url结果页面,根据自定义的采集规则来判断是否收录
附上一个配置及说明
#爬取URL
SeoTool.CrawlUrl=http://www.tianya.cn/new/publicforum/articleslist.asp?pageno=2&stritem=funinfo∂=0&nextarticle=2010-10-11+9%3A38%3A41&strsubitem=&strsubitem2=
<!– 此处一般指定列表页第二页作为起始页,权值稍低,比较有参考价值–>
#爬取URL字符集
SeoTool.CrawlCharset=gbk <!– 指定页面编码–>
#包含字符串1,必填
SeoTool.CrawlKey1=funinfo/ <!– 必填字符串–>
#包含字符串2,选填
SeoTool.CrawlKey2=.shtml <!– 选填字符串–>
#爬取数量
SeoTool.CrawlCount=1000 <!– 抓取页面数量,为避免内存报错,我一般选1000–>
#TXT文件路径,以 / 结尾
SeoTool.CrawlTextPath=D:/收录抽查/ <!– 抓取的url的txt文件储存位置–>
#TXT文件名
SeoTool.CrawlTextFile=20101011娱乐八卦.txt <!– 该txt文件名称–>
#是否生成CSV文件:0,不生成;1,生成。 <!– 想要个csv也可以–>
SeoTool.CrawlCSV=1
#TXT文件路径,以 / 结尾
SeoTool.CrawlCsvPath=D:/收录抽查/ <!– 收录抽查结果也会生成txt文件,3个哦–>
#TXT文件名
SeoTool.CrawlCsvFile=a.csv <!– csv的储存位置–>
#分析使用的搜索引擎 <!– 百度搜索结果页面的采集规则,前两天百度刚改版,还没修改这个规则->
SeoTool.AnalyticSE=http://www.baidu.com/s?wd=
#分析时的开始标记
SeoTool.AnalyticStartTag=把百度设为主页
#分析时的结束标记
SeoTool.AnalyticEndTag=以下是网页中包含
#定义收录标记
SeoTool.AnalyticIncludeTag=
#定义未收录标记 <!– 采集结果有三种状态,未收录,收录,状态不明,熟悉百度搜索结果的可以不深研究了–>
SeoTool.AnalyticNoIncludeTag=抱歉
#TXT文件路径,以 / 结尾
SeoTool.AnalyticTextPath=D:/temp/analytic/
#收录的URL地址TXT文件
SeoTool.AnalyticIncludeTextFile=include.txt
#未收录的URL地址TXT文件
SeoTool.AnalyticNoIncludeTextFile=noinclude.txt
#分析出现歧义的文件
SeoTool.AnalyticAmbiguityTextFile=ambiguity.txt
收录抽查的好处有以下几点:
针对于海量数据的流量趋势判断
随时关注权值变化
随时预期长尾流量
随时关注真实收录趋势
附上天涯社区的2张百度收录变化图
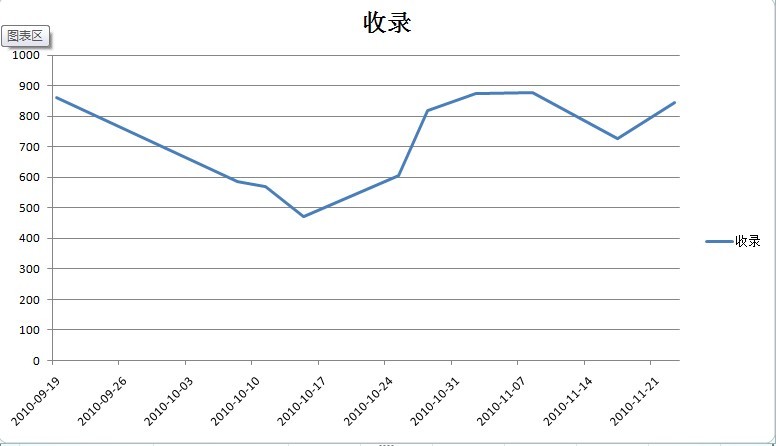
天涯娱乐八卦版块百度收录变化趋势
详细数据如下

可以看到,2010年10月11日左右的收录值急剧下降,最低时平均千条帖子的收录不到50%
原因:对比该时间段内的热点事件为“小月月事件”,这是一个非常悲催的事件,天涯2010年最热门的事件非其莫属,但是,由于程序底层架构不能支持过大流量,导致天涯在全国各省市,各时间段均遇到了访问过慢,不能访问,服务器500等问题,看似火爆的流量点,带来的反而是整体pv在40%左右的下降
同理,在用户不能正常访问的同时,Baiduspider的抓取也遇到问题,最低值时导致收录数量下降40%+,由于是抓取的周数据,真实情况可能会更低,通过收录抽查能及时的发现该问题,另外,百度收录抽查可同样配合google管理员工具中的googlebot抓取来使用。
ps:但解决不解决所发现的问题,就需要看技术人员,运维人员和老板的脑力了。

