在我刚接触SEO的时候,我曾经有去仔细的观察过搜索引擎。一方面做SEO的本身就是靠着搜索引擎而活,我们必须得把这位大哥给伺候好了;再一方面是想看看他是如何工作的,他是如何实现几万个页面能在一秒钟内做到有序排名。在今天其实对于这些问题都已经有了一个比较清晰的概念。
想在某个搜索引擎具有一定的排名,光知道网上的那些SEO基础那完全不够。我也有遇到过一些朋友把自己的站排名做上去了,但他不知道是怎么做上去的。他告诉我的是做做外链,更新更新文章就上去了。我们不能排除有这种可能性毕竟关键词的竞争度都是不一样的。但我遇到过最多的还是做上排名了,但很快又掉下来了,根本不知道如何去保持这个排名。废话也不多说了,跟着何涛的思路一步一步往下走。
首先我们得提一个SEO的专有名词“蛛蛛”。这个也是每个搜索引擎用来爬行和访问页面的一个程序,也叫机器人。这里我为蛛蛛这个名词做一下解释:在我看来,之所以把他称为蛛蛛。是因为蛛蛛都是顺着网上的链接代码来访问互联网上的每个网站,而且每个网站的这些链接其实就像一张非常复杂的网,蛛蛛要做的就是在这张网上抓取信息,这个形式非常类似蛛蛛这个动物,所以也就有了一个形像的比喻。
从蛛蛛这个名词我们是否已经有点感悟了呢?原来搜索引擎的一些必须要更新的数据库与排名顺序都是要靠这么一个程序来抓取、检索才会在定期有个更新。那么也就是说:想让我们的网站有排名,是不是一定得先让搜索引擎收录我们的站,想让搜索引擎收录,是不是又先得让蛛蛛来爬我们的站。其实这里面就会有一个过程,如何让蛛蛛爬行我们的网站这里我也大概的说一下:
一般来说我们把这个方式叫做“链接诱饵”。也就是说通过某种手段吸引蛛蛛来爬行我们的网站。常见的比如去把我们刚做好的网站提交给搜索引擎、通过在高权重的网站发布链接、通过搜索引擎的种子站来做引导等,这些都是比较好用的办法。
我们再来看一下蛛蛛他的一些习惯,好让我们更好的掌握它,从而不断的给他喂食,培养蛛蛛访问网站的速度与习惯从而提高网站的权重获得一定的排名
说到蛛蛛习惯我们不得不得一个概念“深度优先、广度优先”。前面我们已经有说到蛛蛛最终还是个程序,能牵引他爬行的是网站与网站之间的链接。大家有没有印象在看一些SEO基础教程的时候,都有说到一个网站的结构一定要树形,而且目录级别不要过深。其实这点的说法就来源于深度优先与广度优先。
深度优先:比如蛛蛛访问一个网站的链接,他就会一直顺着这个链接一直往下爬,直到前面再也没有链接的时候然后再返回第一个页面,沿着另外一个链接再向前爬。好比蛛蛛访问我们的网站首页,从它的一个爬行习惯必定会是从导航里的一个栏目一直往下爬行,可能爬到我们的最终页就再次返回。
广度优先:这个与深度优先有点不一样,这个方式的表现形式当蛛蛛在一个页面上发现多个链接的时候,他会先把第一层链接都爬一遍,然后再沿着第二层页面上发现的链接爬向下一层。下面我给大家看张图就会明白了
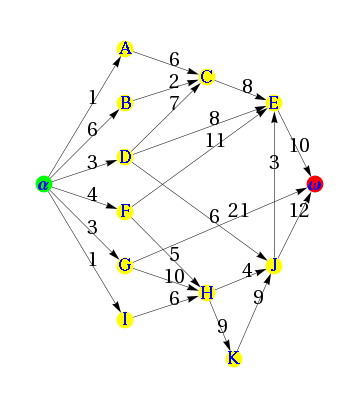
其实在我们现实中,蛛蛛他往往是把广度优先与深度优先相结合来使用的,这样就可以尽可能的照顾到多的网站(广度优先),也能照顾到一一部分网站的内页(深度优先)
有了这样的数据抓取原理,搜索引擎必定会把这些通过蛛蛛抓取回来的信息首先做一个初步的整理与存储,并会对每一个信息给予特定的编号。
上面只是说到搜索引擎的一些基本的抓取情况,对于他的进一步是如何处理请继续关注从搜索引擎工作原理折射出的SEO知识(中)
文章摘自:宁波何涛SEO博客:http://www.nb-seoer.com/post/153.html
感谢 何涛 的投稿

