前面我们讲个搜索引擎如何搜集网页,今天说下第二个过程网页预处理,其中中文分词就显得尤其重要,下面就详细讲解一下搜索引擎是怎么进行网页预处理的:
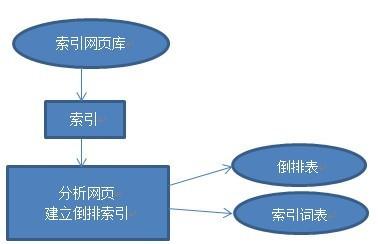
网页预处理的第一步就是为原始网页建立索引,有了索引就可以为搜索引擎提供网页快照功能;接下来针对索引网页库进行网页切分,将每一篇网页转化为一组词的集合;最后将网页到索引词的映射转化为索引词到网页的映射,形成倒排文件(包括倒排表和索引词表),同时将网页中包含的不重复的索引词汇聚成索引词表。如下图所示:
一个原始网页库由若干个记录组成,每个记录包括记录头部信息(HEAD)和数据(DATA),每个数据由网页头信息(header),网页内容信息(content)组成。索引网页库的任务就是完成给定一个URL,在原始网页库中定位到该URL所指向的记录。
如下图所示:

对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。中文自动分词是网页分析的前提。文档由被称作特征项的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词(或中文切词)。切词软件中使用的基本词典包括词条及其对应词频。
自动分词的基本方法有两种:基于字符串匹配的分词方法和基于统计的分词方法。
1) 基于字符串匹配的分词方法
这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长匹配,和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
1. 正向最大匹配;
2. 逆向最大匹配;
3. 最少切分(使每一句中切出的词数最小)。
还可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
对于机械分词方法,可模型化表示为ASM(d,a,m),即 Automatic Segmentation Model。其中,
d:匹配方向,+表示正向,-表示逆向;
a:每次匹配失败后增加或减少字串长度(字符数),+为增字,-为减字;
m:最大或最小匹配标志,+为最大匹配,-为最小匹配。
例如,ASM(+, -, +)就是正向减字最大匹配法(Maximum Match based approach,MM),ASM(-, -, +)就是逆向减字最大匹配法(简记为RMM方法)。
2)基于统计的分词方法
从形式上看,词是稳定的字的组合,因此上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。
可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。
互现信息体现类汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。
实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
感谢 落枫seo 的投稿

