本系列文章基于公开资料对Google App Engine的实现机制这个话题进行深度探讨。在切入Google App Engine之前,首先会对Google的核心技术和其整体架构进行分析,以帮助大家之后更好地理解Google App Engine的实现。
本篇将主要介绍Google的十个核心技术,而且可以分为四大类:
1.分布式基础设施:GFS、Chubby 和 Protocol Buffer。
2.分布式大规模数据处理:MapReduce 和 Sawzall。
3.分布式数据库技术:BigTable 和数据库 Sharding。
4.数据中心优化技术:数据中心高温化、12V电池和服务器整合。
分布式基础设施
GFS
由于搜索引擎需要处理海量的数据,所以Google的两位创始人Larry Page和Sergey Brin在创业初期设计一套名为“BigFiles”的文件系统,而GFS(全称为“Google File System”)这套分布式文件系统则是“BigFiles”的延续。
首先,介绍它的架构,GFS主要分为两类节点:
1.Master节点:主要存储与数据文件相关的元数据,而不是Chunk(数据块)。元数据包括一个能将64位标签映射到数据块的位置及其组成文件的表格,数据块副本位置和哪个进程正在读写特定的数据块等。还有Master节点会周期性地接收从每个Chunk节点来的更新(“Heart-beat”)来让元数据保持最新状态。
2.Chunk节点:顾名思义,肯定用来存储Chunk,数据文件通过被分割为每个默认大小为64MB的Chunk的方式存储,而且每个Chunk有唯一一个64位标签,并且每个Chunk都会在整个分布式系统被复制多次,默认为3次。
下图就是GFS的架构图:
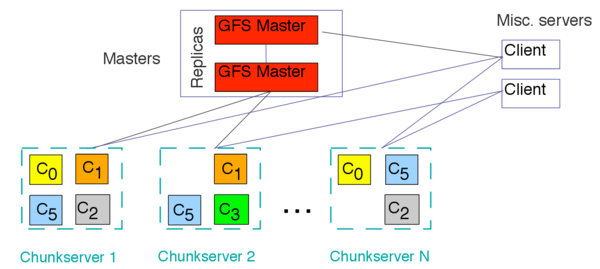
图1. GFS的架构图(参片[15])
接着,在设计上,GFS主要有八个特点:
1.大文件和大数据块:数据文件的大小普遍在GB级别,而且其每个数据块默认大小为64MB,这样做的好处是减少了元数据的大小,能使Master节点能够非常方便地将元数据放置在内存中以提升访问效率。
2.操作以添加为主:因为文件很少被删减或者覆盖,通常只是进行添加或者读取操作,这样能充分考虑到硬盘线性吞吐量大和随机读写慢的特点。
3.支持容错:首先,虽然当时为了设计方便,采用了单Master的方案,但是整个系统会保证每个Master都会有其相对应的复制品,以便于在Master节点出现问题时进行切换。其次,在Chunk层,GFS已经在设计上将节点失败视为常态,所以能非常好地处理Chunk节点失效的问题。
4.高吞吐量:虽然其单个节点的性能无论是从吞吐量还是延迟都很普通,但因为其支持上千的节点,所以总的数据吞吐量是非常惊人的。
5.保护数据:首先,文件被分割成固定尺寸的数据块以便于保存,而且每个数据块都会被系统复制三份。
6.扩展能力强:因为元数据偏小,使得一个Master节点能控制上千个存数据的Chunk节点。
7.支持压缩:对于那些稍旧的文件,可以通过对它进行压缩,来节省硬盘空间,并且压缩率非常惊人,有时甚至接近90%。
8.用户空间:虽然在用户空间运行在运行效率方面稍差,但是更便于开发和测试,还有能更好利用Linux的自带的一些POSIX API。
现在Google内部至少运行着200多个GFS集群,最大的集群有几千台服务器,并且服务于多个Google服务,比如Google搜索。但由于GFS主要为搜索而设计,所以不是很适合新的一些Google产品,比YouTube、Gmail和更强调大规模索引和实时性的Caffeine搜索引擎等,所以Google已经在开发下一代GFS,代号为“Colossus”,并且在设计方面有许多不同,比如:支持分布式Master节点来提升高可用性并能支撑更多文件,Chunk节点能支持1MB大小的chunk以支撑低延迟应用的需要。
感谢 SEO拓荒者 的投稿

